



Introduction
The major point the organization moving to the cloud from maintaining their data centers is the leverage that they should not have to waste their money and time in maintaining the server themselves. But while moving to the Cloud the bill of the cloud service can be huge if not optimized carefully.
So AWS cost optimization is important work to do to maintain the cost as low as possible. We can delete the resources that are not currently available.
About The Project
Here in the project, we'll create a Lambda function that identifies EBS snapshots that are no longer associated with any active EC2 instance and deletes them to save on storage costs. [ Lambda Function ]
Step 1: We will create the EC2 instance first and then create the snapshot of the volume attached to the instances.

While we create the Instance the Volume is also created. Now let's Create the Snapshot out of the Volume.

Now By Clicking "Create Snapshot" we create the snapshot out the Volume we created during the instance creation.

We create two snapshots one of which is attached to the Volume ( with Volume size 8 GiB) and one which is not attached to the Volume ( with Volume Size 1 GiB )
Step 2: We will create a lambda function that actually identifies the unassociated snapshot.

We have created the Lambda Function with the role
We have written the Code of the lambda function in Python as
import boto3
def lambda_handler(event, context):
ec2 = boto3.client('ec2')
# Get all EBS snapshots
response = ec2.describe_snapshots(OwnerIds=['self'])
# Get all active EC2 instance IDs
instances_response = ec2.describe_instances(Filters=[{'Name': 'instance-state-name', 'Values': ['running']}])
active_instance_ids = set()
for reservation in instances_response['Reservations']:
for instance in reservation['Instances']:
active_instance_ids.add(instance['InstanceId'])
# Iterate through each snapshot and delete if it's not attached to any volume or the volume is not attached to a running instance
for snapshot in response['Snapshots']:
snapshot_id = snapshot['SnapshotId']
volume_id = snapshot.get('VolumeId')
if not volume_id:
# Delete the snapshot if it's not attached to any volume
ec2.delete_snapshot(SnapshotId=snapshot_id)
print(f"Deleted EBS snapshot {snapshot_id} as it was not attached to any volume.")
else:
# Check if the volume still exists
try:
volume_response = ec2.describe_volumes(VolumeIds=[volume_id])
if not volume_response['Volumes'][0]['Attachments']:
ec2.delete_snapshot(SnapshotId=snapshot_id)
print(f"Deleted EBS snapshot {snapshot_id} as it was taken from a volume not attached to any running instance.")
except ec2.exceptions.ClientError as e:
if e.response['Error']['Code'] == 'InvalidVolume.NotFound':
# The volume associated with the snapshot is not found (it might have been deleted)
ec2.delete_snapshot(SnapshotId=snapshot_id)
print(f"Deleted EBS snapshot {snapshot_id} as its associated volume was not found.")
We fetch all EBS snapshots owned by the same account ('self') and also retrieve a list of active EC2 instances (running and stopped). For each snapshot, it checks if the associated volume (if exists) is not associated with any active instance. If it finds a stale snapshot, it deletes it, effectively optimizing storage costs.
We will trigger it manually by running the test case, we can also use the cloud watch to trigger the lambda function.
Step 3: We need to pass the permission to the role attached to the lambda function the access to describe the instances and snapshots.
We have to provide access to describe snapshots, describe instances, and delete snapshots as well as describe Volume to the role of the Lamba function.
We will have to create a new Policy :
We will Select the service as EC2 provide the Describe snapshot and delete the snapshot.
We again create another Policy to provide the Describe the Instance and describe the volume access.
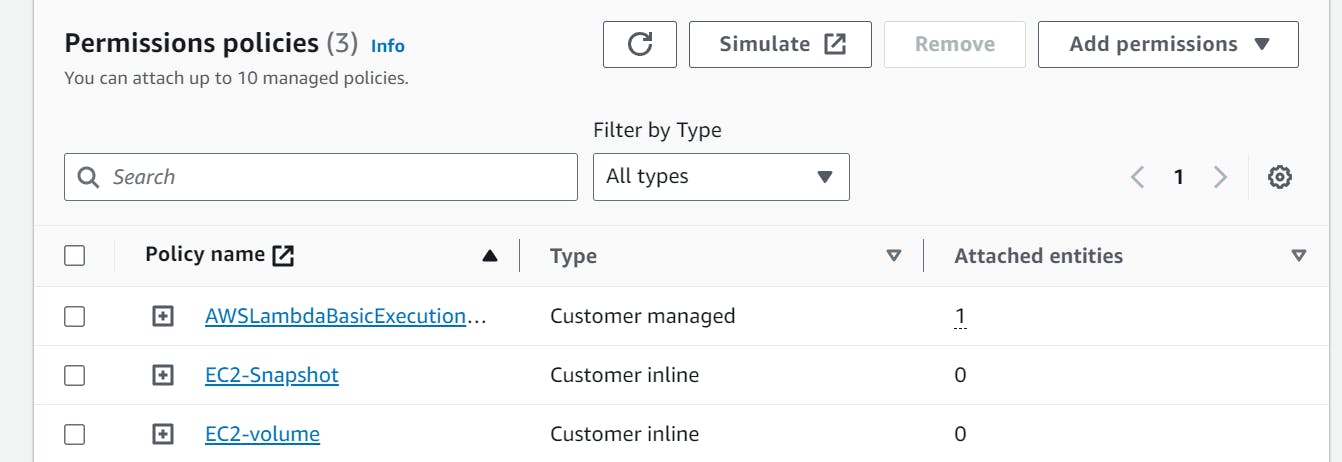
These are the Policies attached to the Lambda Role.
After giving the permission we will run the lambda function and it will look after the snapshot whose volume is not attached to the instance and delete those snapshots.
Step 4: We will Run the lambda Function and check for the result.
We have run the lambda function manually and the function found the one snapshot whose volume is not attached to the instance ( Snapshot we provide above in Step 1).
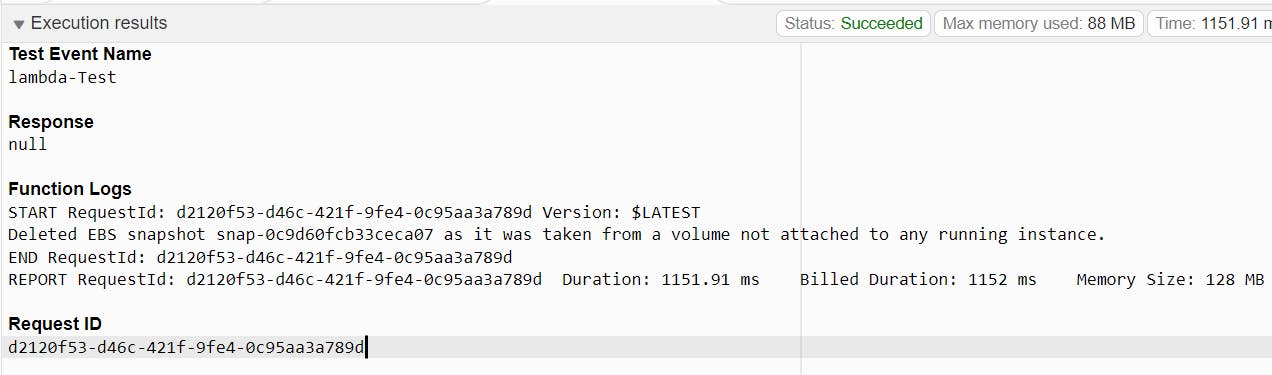
After that, we look at the snapshot and the snapshot is deleted as per the condition.

As we can see the Snapshot is deleted whose volume is not attached to the ec2 instances.
BEFORE :

More About Cost Optimization
This is one of the situations where the developer may have created the snapshot and while deleting the instance he may have forgotten to delete the snapshot. So the DevOps engineer can use the lambda functions to reduce the cost by deleting the unwanted instance. We can do many other things for Cost Optimization, this is just an example of how can we reduce the overall Cost.
Things to consider in Cost Optimization
There are many techniques we can use to carefully design our architecture to ensure less charge, here are some of the things we can consider.
1) Right-Sizing :
"Right-sizing" refers to the practice of matching our cloud resources (such as EC2 instances, databases, and other AWS services) to the actual computing needs of our applications. It involves selecting the appropriate size and type of resources to minimize costs while ensuring our workloads perform optimally. For eg: We can reduce our instance type if the CPU consumption in the instance is less than like 80%. We can use the S3 glacier service to store less used large amounts of data.
2) Ingress and Egress
We should also keep in mind while designing our architecture the cost it takes for the data transfer between AWS services and the internet. The AWS charges are different for internal data transfer and external data transfer. AWS charges data transfer between different regions and availability zones. So it is best to practice keeping in mind the internal data flow as well.
3) Data retention
It refers to the practice of determining how long we should keep data within AWS services based on business, compliance, and cost-efficiency considerations. For eg: The cloud watch logs are high and it can significantly increase the overall cost so we can move the logs to the cheaper option like S3 galcier after some time as per the requirement. We should constantly monitor and delete the resources we haven't used for a long time.
Some of the other things we should do for cost optimization is Using the Pricing Calculator to find out the exact charge we are going to ensure and We should design our architecture by considering Price in mind.
Conclusion
To Conclude, in this cloud optimization, we have performed one of the ways we can use the AWS services to monitor and perform the activities resulting in cost Optimization.